SSD
The performance of SSD is much better than YOLO (2016).
Key Points
Prediction on top of Feature Map
Say if for a specific convolutional layer, the feature map is “m x n x p”, SSD will use 3 x 3 x p to do convolution with the feature map and get the prediction values.
n classes of Object, plus background
So there is n + 1 classes. That means for a specific prediction bounding box, there are n + 1 confidence values.
To make it simple let’s say n + 1 = c.
For each box, SSD will predict another four values: (cx, cy, w, h), so for a specific bounding box, there will be (c + 4) values to be predicted.
How many bound box?
Let’s say the feature map is m x n, that’s to say we have m x n blocks. In SSD, it will select k default boxes. So we have to predict m x n x k boxes.
How may prediction values for one feature map?
So for this specific feature map, we have mnk(c+4) prediction values.
So for the feature map of m x n x p, after the prediction layer, the output value would be mnk(c+1).
VGG16
The base net of SSD is VGG16. So what is VGG16? Refer to below figure:
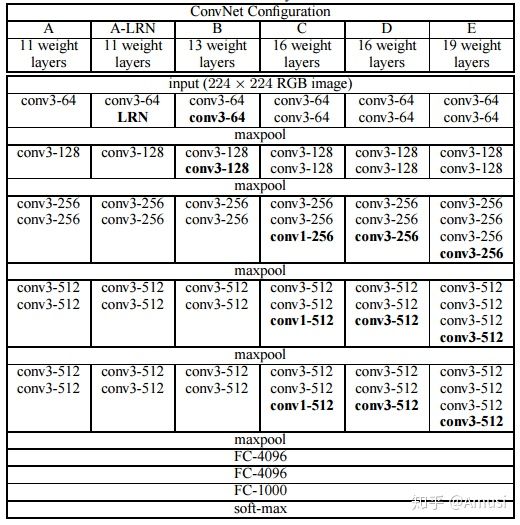
There are 13 convolution layers and 3 Full connection layers (FC6, FC7, FC8). Total 16 layers (That’s why it is called VGG16).
- FC6: FC-4096
- FC7: FC-4096
- FC8: FC-1000
What is changed on SSD?
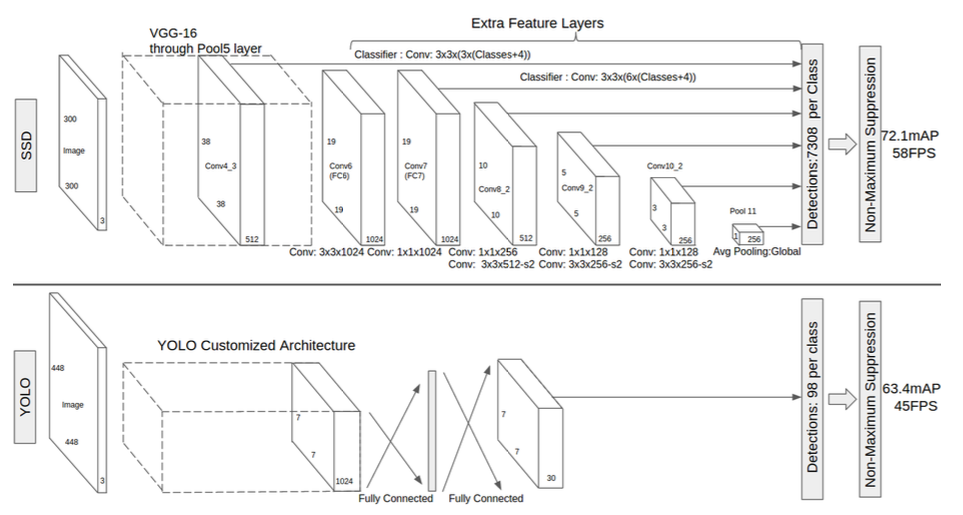
- FC6 (See “FC6” in the figure): Replaced with Conv6 3x3x1024
- FC7 (See “FC7” in the figure): Replaced with Conv7 1x1x1024
- FC8 (See “FC78 in the figure): Replaced with Conv8_2
- Conv9_2: new added
- Conv10_2: new added
Feature Map used
From above figure, we could also know the feature map used:
- Conv4_3 (38x38)
- Conv7 (19x19)
- Conv8_2 (10x10)
- Conv9_2 (5x5)
- Conv10_2 (3x3)
- Conv11_2 (1x1)
Default Box
- Conv4_3: Since the feature map is 38 x 38 which is big in size, it only put 3 default box.
- For other feature map: uses 6 default boxes.
Prediction from feature map
From the paper:
For a feature layer of size m × n with p channels, the basic element for predicting parameters of a potential detection is a 3 × 3 × p small kernel that produces either a score for a category, or a shape offset relative to the default box.
What does it mean?
See below figure, it uses 3x3 convolution to generate localization and classification confidence.
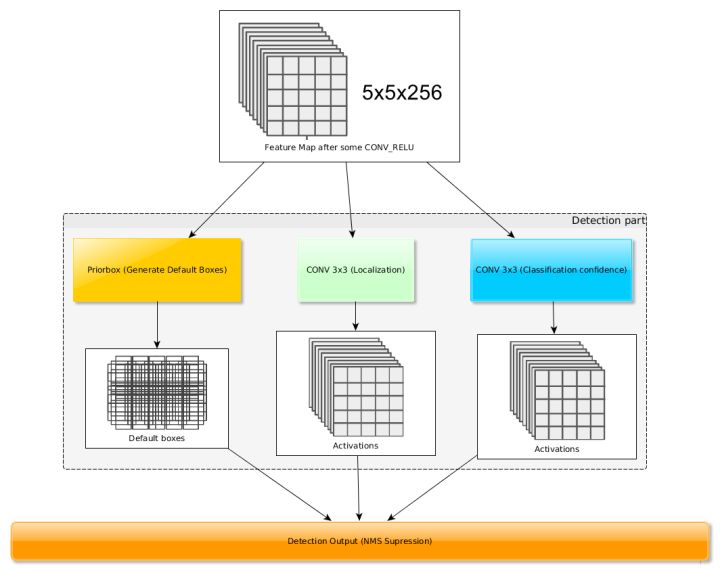
Convert (cx, cy, w, h) to coordination
(cx, cy ,w, h) is not the real coordination. The real coordination would be got by transforming from the predicted (cx, cy, cw, ch). How?
Let’s say the default box’s real coordination is (dx, dy, dw, dh).
real_x = dx + cx * variances[0] * dw
real_y = dy + cy * variances[0] * dh
real_w = dw * exp(cw * variances[1])
real_h = dh * exp(ch * variances[1])